谢磊
西北工业大学教授 · 音频语音与语言处理实验室(ASLP)负责人

谢磊,西北工业大学计算机学院教授、博士生导师,音频语音与语言处理实验室(ASLP@NPU)负责人。主要研究方向包括语音处理、对话式人工智能,以及面向语音与语言技术的先进神经网络模型与大模型技术,在语音增强、自动语音识别、语音合成与语音对话等领域开展了系统性研究。
他长期致力于建设面向学术界的开源工具与数据资源,指导了被广泛使用的 WeNet 语音识别工具包和 WenetSpeech 开源语音数据系列等项目。
他曾获得多项荣誉,包括教育部新世纪优秀人才支持计划、陕西省青年科技新星、全球前2%顶尖科学家(斯坦福大学 & Elsevier)以及华为云 AI 名师等。已发表论文 400 余篇,Google Scholar 引用超过 18000 次,H-index 为 63。曾获多项国际会议最佳论文奖及国际评测冠军,诸多研究成果已实现产业落地。现任 ISCA SIG-CSLP 副主席,并担任 IEEE/ACM TASLP 与 IEEE SPL 的高级领域编委(SAE)。
地址:西安市长安区西北工业大学长安校区计算机学院 207 室
展开详细简介
谢磊,西北工业大学计算机学院教授、博士生导师,音频语音与语言处理实验室(ASLP@NPU)负责人。其研究聚焦于语音处理、对话式人工智能,以及面向语音与语言技术的先进神经网络模型,在语音增强、自动语音识别和语音合成等方向做出了重要贡献。
他也长期致力于面向学术界建设开源研究基础设施,指导了被广泛使用的 WeNet 语音识别工具包以及 WenetSpeech 开源语音数据系列等项目。
谢磊博士于西北工业大学获得计算机工程博士学位,博士阶段主要从事语音识别研究。在加入西北工业大学任教之前,曾在比利时布鲁塞尔自由大学(Vrije Universiteit Brussel)、香港城市大学和香港中文大学从事科研工作。
他曾获得多项荣誉,包括教育部新世纪优秀人才支持计划、陕西省青年科技新星、全球前2%顶尖科学家(斯坦福大学 & Elsevier)以及华为云 AI 名师等。
谢磊教授已在音频、语音与语言处理领域发表400余篇同行评议论文,Google Scholar 引用超过 18000 次,H-index 为 63。其研究成果曾多次获得国际学术会议最佳论文奖,并在多项国际评测竞赛中取得冠军。诸多研究成果也已成功应用于产业实践。
在 ASLP@NPU,他指导着一批背景多元的学生和研究人员,围绕语音、音频与语言智能开展前沿研究。他也长期活跃于国际学术共同体,担任多个学术组织和期刊的重要职务。目前,他担任国际语音通信协会 ISCA 中文口语语言处理兴趣组(SIG-CSLP)副主席,以及 IEEE/ACM Transactions on Audio, Speech, and Language Processing 和 IEEE Signal Processing Letters 的高级领域编委(Senior Area Editor)。
高光成果

开源!SoulX-Transcriber——面向复杂对话的端到端多说话人语音转录框架来啦!
详细了解 >
SmoothConv & DuplexConv:面向对话式 AI 的大规模中文全双工语音数据集开源!
详细了解 >新闻公告
| Jun 06, 2026 | 11 篇论文被语音研究旗舰会议 Interspeech 2026 录用! |
|---|---|
| Jun 06, 2026 | 我们联合 Soul APP 和 MoonStep AI 开源了多说话人语音转写模型 SoulX-Transcriber,在多个公开基准上获得最佳性能! |
| May 19, 2026 | 我们联合 WeNet 开源社区推出了 S2Accompanist,以402M轻量参数斩获 ICME 2026 ATTM 效率赛道冠军! |
| May 19, 2026 | 我们很高兴宣布,第二届多语言对话式语音语言模型挑战赛(MLC-SLM)设立总计 2 万美元奖金池。欢迎参与挑战,赢取大奖! |
| Apr 20, 2026 | IEEE SLT 2026 SmartGlasses 挑战赛盛大开启!聚焦第一视角下的真实社交语音交互 |
| Apr 10, 2026 | 2026 届硕士同学顺利毕业,人均 6+offer,获选腾讯青云计划,京东顶尖青年技术天才计划等,入职阿里巴巴(Alibaba)、腾讯(Tencent)、京东(JD.com)等业界头部企业或读博深造。祝贺! |
| Apr 07, 2026 | WenetSpeech-Wu —— 迄今为止最大的吴语数据集(Wu Chinese dataset),已被 ACL 2026 接收 |
| Apr 07, 2026 | LLM-forced Aligner —— Qwen3-ForcedAligner 背后的核心技术,已被 ACL 2026 接收 |
| Apr 05, 2026 | 恭喜姚继珣博士获得腾讯青云计划,入职腾讯! |
| Mar 17, 2026 | 4 篇论文被 ICME 2026 录用 |
实验室
音频语音与语言处理实验室(ASLP@NPU)由西北工业大学谢磊教授领衔,是国内外语音、音频与语言智能领域具有广泛影响力和知名度高的研究团队。实验室围绕语音识别、语音合成、语音增强、口语对话系统以及新兴音频语言模型等方向开展前沿研究,始终坚持学术创新与实际应用并重。
ASLP@NPU 高度重视科研成果的工程化与产业落地,长期与工业界保持紧密而深入的合作关系。实验室多项研究成果已成功应用于实际场景,所建设的 WeNet 工具平台与 WenetSpeech 数据资源也已被学术界和工业界广泛采用。
实验室同时高度重视人才培养,已为语音与人工智能领域培养了大批优秀人才,众多毕业生和成员已成长为头部科技企业和科研机构中的技术领军人物、资深研究人员与核心技术骨干。
通过融合学术深度、工程能力与产业视野,ASLP@NPU 持续推动语音智能与下一代人机交互技术的发展。
开源项目概览
- SoulX-Transcriber — 面向复杂对话的端到端多说话人语音转录框架
- YingMusic-Singer+ — 支持灵活歌词操控与无标注旋律引导的可控歌声合成
- SoulX-Podcast — 基于文本生成高保真播客,支持多人对话、多种方言
- DiffRhythm — 基于潜在扩散的端到端全长歌曲生成模型
- OSUM — 面向学术有限资源的开放语音理解模型
- SongEval — 歌曲美学评估工具包
- WenetSpeech-Yue — 大规模多维度标注粤语语音语料库
- MeanVC — 基于均值流的轻量级流式零样本语音转换
- VoiceSculptor — 基于 LLaSA 和 CosyVoice2 的指令式语音合成方案
- WenetSpeech-Chuan — 大规模四川方言语音语料库
- DiffRhythm2 — 基于块流匹配的高效高保真歌曲生成
- WenetSpeech-Wu-Repo — 大规模吴方言语音语料库
- SongFormer — 超快超准音乐标注神器
近期论文

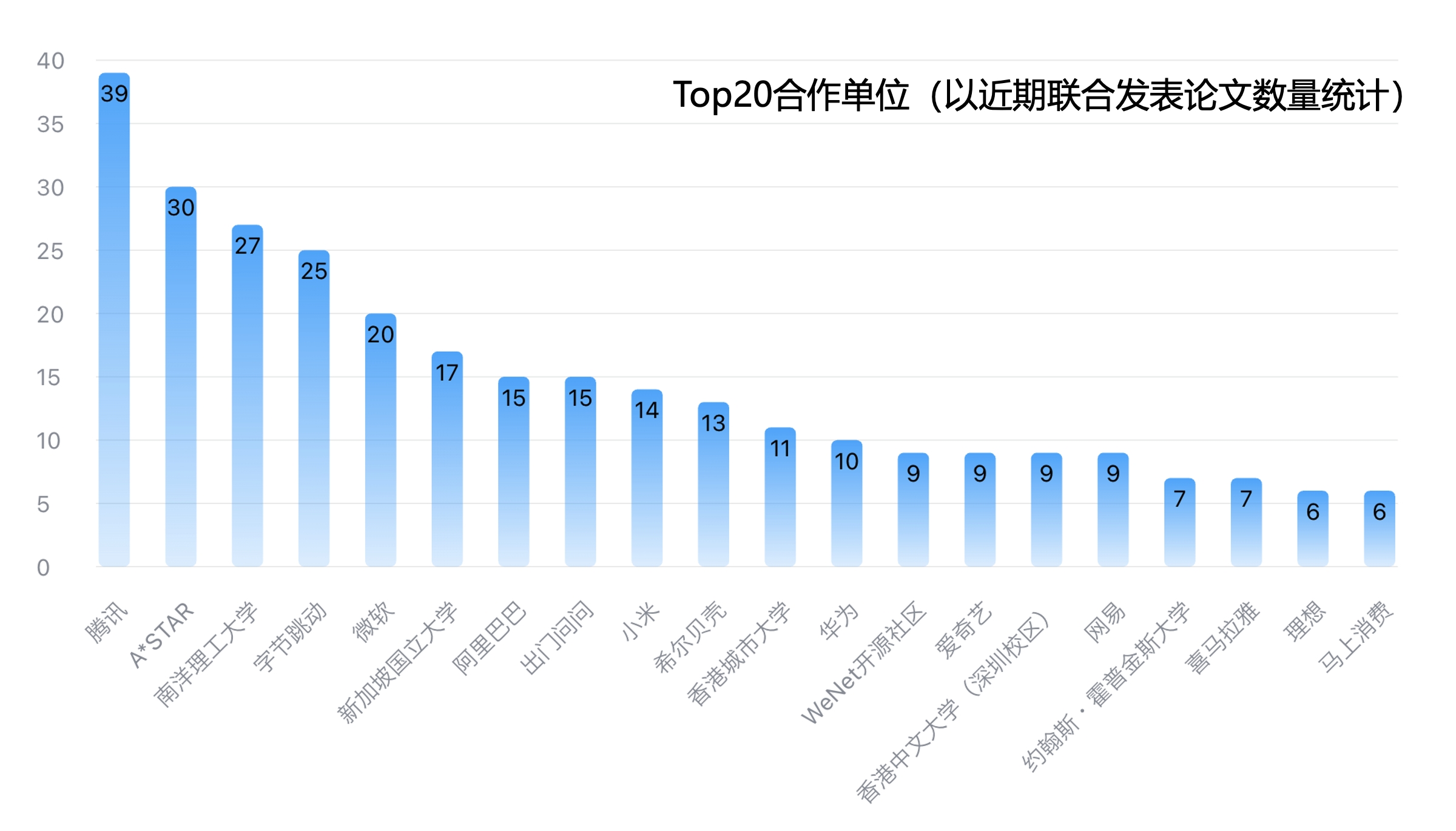
学术兼职
- Senior Area Editor, IEEE/ACM Transactions on Audio, Speech, and Language Processing
- Senior Area Editor, IEEE Signal Processing Letters
- Member, IEEE Speech and Language Processing Technical Committee (SLTC)
- Vice Chairperson (2022–2024), ISCA Special Interest Group on Chinese Spoken Language Processing (SIG-CSLP)
- Board Member (2020–2023), APSIPA Speech and Language Processing (SLP) Technical Committee
获奖
- 季军, Single Track, Interspeech 2026 Audio Reasoning Challenge
- 冠军, In-Domain Singing Style Conversion Track, ASRU 2025 The Singing Voice Conversion Challenge
- 冠军, Zero-Shot Singing Style Conversion Track, ASRU 2025 The Singing Voice Conversion Challenge
- 冠军, 通用音频分离赛道, NCMMSC 2025 CCF 先进音频技术竞赛
- 亚军, Target Speaker Lipreading Track, ICME 2024 Chat-scenario Chinese Lipreading (ChatCLR) Challenge
- 冠军, Source Speaker Verification Against Voice Conversion Track, SLT 2024 Source Speaker Tracing Challenge(SSTC)
- 冠军, ICASSP 2024 Packet Loss Concealment (PLC) Challenge
- 亚军, Real-time Track, ICASSP 2024 Speech Signal Improvement Challenge
- 季军, Non-real-time Track, ICASSP 2024 Speech Signal Improvement Challenge
- 亚军, ICASSP 2024 Multimodal Information based Speech Processing (MISP) Challenge
- 冠军, 多模态远距离拾音赛道,2024中国声学学会声华杯声学技术大赛
- 冠军, 单说话人视觉语音识别赛道, NCMMSC 2024 中文连续视觉语音识别挑战赛 (CNVSRC)
- 冠军, 多说话人视觉语音识别赛道, NCMMSC 2024 中文连续视觉语音识别挑战赛 (CNVSRC)
- 冠军, SLT 2024 Low-Resource Dysarthria Wake-Up Word Spotting Challenge(LRDWWS Challenge)
- 冠军, Speech-to-Speech Translation (Offline) Track, ACL 2023 Speech-to-Speech Translation (S2ST)
- 冠军, Any-to-one, In-domain Singing Voice Conversion Track, ASRU 2023 The Singing Voice Conversion Challenge
- 亚军, Any-to-one, Cross-domain Singing Voice Conversion Track, ASRU 2023 The Singing Voice Conversion Challenge
- 亚军, Audio-Visual Target Speaker Extraction (AVTSE) Track, ICASSP 2023 Multi-modal Information based Speech Processing (MISP) Challenge
- 冠军, UDASE (Unsupervised Domain Adaptation for Speech Enhancement) Track, Interspeech 2023 CHiME Speech Separation and Recognition Challenge (CHiME-7)
- 冠军, Non-personalized AEC Track, ICASSP 2023 Acoustic Echo Cancellation Challenge (AEC Challenge)
- 亚军, Personalized AEC Track, ICASSP 2023 Acoustic Echo Cancellation Challenge (AEC Challenge)
- 亚军, Audio-Visual Diarization & Recognition Track, ICASSP 2023 Multimodal Information based Speech Processing (MISP) - Challenge
- 季军, Audio-Visual Speaker Diarization Track, ICASSP 2023 Multimodal Information based Speech Processing (MISP) Challenge
- 冠军, Headset Speech Enhancement Track, ICASSP 2023 Deep Noise Suppression Challenge
- 冠军, Speakerphone Speech Enhancement Track, ICASSP 2023 Deep Noise Suppression Challenge
- 冠军, 语音增强赛道, 2023 声华杯声学技术大赛
- 冠军, ASRU 2023 MultiLingual Speech processing Universal PERformance Benchmark (SUPERB)
- 冠军, 单说话人视觉语音识别赛道, NCMMSC 2023 中文连续视觉语音识别挑战赛 (CNVSRC)
- 冠军, 多说话人视觉语音识别赛道, NCMMSC 2023 中文连续视觉语音识别挑战赛 (CNVSRC)
- 2023年度华为云AI名师奖
- 冠军, Speaker Anonymization Track, Interspeech 2022 VoicePrivacy 2022 Challenge (VPC 2022)
- 亚军, Fully-supervised Track, Interspeech 2022 Far-field Speaker Verification Challenge (FFSVC)
- 亚军, Semi-supervised Track, Interspeech 2022 Far-field Speaker Verification Challenge (FFSVC)
- 亚军, ISCSLP 2022 Magichub Code-Switching ASR Challenge
- 季军, ISCSLP 2022 Conversational Short-phrase Speaker Diarization Challenge
- 冠军, Constrained Track, O-COCOSDA 2022 Indic Multilingual Speaker Verification Challenge (I-MSV)
- 季军, Unconstrained Track, O-COCOSDA 2022 Indic Multilingual Speaker Verification Challenge (I-MSV)
- 季军, NCMMSC 2022 面向蒙古语的低资源语音合成竞赛
- 2022年度华为云优秀合作伙伴奖
- 2022华为云优秀创新合作团队
- 亚军, Training with VoxCeleb 1/2 Only Track, VoxSRC 2021 Workshop 2021 VoxCeleb Speaker Recognition Challenge (VoxSRC)
- 亚军, Additional Public Data Allowed (e.g., MUSAN, RIR) Track, VoxSRC 2021 Workshop 2021 VoxCeleb Speaker Recognition - Challenge (VoxSRC)
- 季军, Real-Time Wideband Speech Enhancement Track, Interspeech 2021 Deep Noise Suppression Challenge (DNS Challenge)
- 季军, Real-Time AEC & Speech Enhancement Track, Interspeech 2021 Acoustic Echo Cancellation Challenge (AEC Challenge)
- 冠军, Close-talking Single-channel Track, ISCSLP 2021 Personalized Voice Trigger Challenge (PVTC)
- 冠军, Real-Time Wideband Speech Enhancement Track, Interspeech 2020 Deep Noise Suppression Challenge (DNS Challenge)
- 亚军, Non-Real-Time Wideband Speech Enhancement Track, Interspeech 2020 Deep Noise Suppression Challenge (DNS Challenge)
- 华为2020年优秀技术成果合作奖
- 冠军, Closed-set Word-level Audio-Visual Speech Recognition Track, ICMI 2019 Mandarin Audio-Visual Speech Recognition - Challenge
- 2019-2020年度美团科研合作实践奖
- 季军, Interspeech 2018 CHiME Speech Separation and Recognition Challenge (CHiME-5)
- 亚军, Unsupervised Subword Unit Modeling Track, Interspeech 2017 Zero Resource Speech Challenge
- 冠军, Spoken Term Discovery Track, Interspeech 2015 Zero Resource Speech Challenge
- 冠军, QUESST (Query-by-Example Speech Search) Track, MediaEval Multimedia Benchmark Workshop 2015 Query-by-Example Search on Speech Task (QUESST)
- 亚军, QUESST (Query-by-Example Speech Search) Track, MediaEval Multimedia Benchmark Workshop 2014 Query-by-Example Search on Speech Task (QUESST)